这学期老师让我研究图神经网络(GNN),但是这玩意有点大。一方面可以研究GNN的理论,解决目前GNN存在的问题;另一方面可以研究GNN的应用。跟老师详细探讨之后,发现老师想让我研究GNN在Few-Shot Learning上的应用。
上周读了几篇论文,想要总结一下。看看会不会有什么新的想法。
问题定义
其实,GNN可以用在四种学习任务中:Few-shot Learning、Zero-Shot Learning、Semi-supervised Learning和Avtive Learning。那么具体这几种任务有何区别呢?下面我们对这几种任务进行详细的说明及区分。
这几个问题都可以应用在不同的问题中,例如小样本目标检测,小样本数据分类。这里我的主要研究方向主要为小样本数据分类。所以下面的主要阐述均是针对小样本数据分类而言的。
不同于之前我们epoch、iteration的概念。在这些问题中,称一个task为episodic。那么什么叫做一个task呢?
对于任务$i$而言,从部分有标签且服从独立同分布$p$的图像样本集合中抽取任务$\left(\mathcal{T}_{i}, Y_{i}\right)_{i}$,其满足如下通项
其中,$s$表示有类标样本的数目,称为support sets(支撑集);$r$表示无类标样本的数目;$t$表示待分类样本的个数,即Query sets(查询集);$K$为类别数目。$\mathcal{P}_{l}\left(\mathbb{R}^{N}\right)$表示特定类别在$\mathbb{R}^{N}$上的分布。
为什么假设独立同分布呢?机器学习就是利用当前获取到的信息(或数据)进行训练学习,用以对未来的数据进行预测、模拟。所以都是建立在历史数据之上,采用模型去拟合未来的数据。因此需要我们使用的历史数据具有总体的代表性。为什么要有总体代表性?我们要从已有的数据(经验) 中总结出规律来对未知数据做决策,如果获取训练数据是不具有总体代表性的,就是特例的情况,那规律就会总结得不好或是错误,因为这些规律是由个例推算的,不具有推广的效果。而通过独立同分布的假设,就可以大大减小训练样本中个例的情形。
给定大小为$L$的训练集合$\left\{\left(\mathcal{T}_{i}, Y_{i}\right)_{i}\right\}_{i \leq L}$(即有$L$个task),标准的监督学习目标为:
其中$\Phi(\mathcal{T} ; \Theta)=p(Y | \mathcal{T})$为模型,从这个表达式中可以看出来,可以将模型看做是后验推理过程;$\mathcal{R}$为标准正则化。$\ell$为损失函数,例如交叉熵等。
Few-shot Learning
在式子$({1})$中,当$r=0, t\neq0,s=qK$的时候,即为Few-Shot Learning的定义。此时,一共有$K$个类别,每一个类别,都有$q$个已有标签的数据,称为q-shot, K-way学习。常见的的有5-way,1-shot和5-way,5-shot。
Zero-Shot Learning
与Few-Shot Learning相同,这里的$r=0, t=0$。不同点在于,假定所有的类别为$\mathcal{C}$,$\mathcal{C_{tr}}$表示训练集类别,$\mathcal{C_{tr}}$表示训练集类别,$\mathcal{C_{te}}$表示验证集类别,Zero-Shot Learning问题中要保证$\mathcal{C}_{t e} \cap \mathcal{C}_{t r}=\emptyset$,即测试集的类别不能出现在训练集类别中;除此之外,还有一点区别在于,在测试集中,Zero-Shot Learning所有数据均没有类标,而Few-Shot Learning可以有部分数据有类标。
Few-Shot Learning中也可以测试集的类别不能出现在训练集类别中。
Semi-supervised Learning
与Few-Shot Learning不同的是,在Semi-supervised Learning学习中,$r>0,t\neq0$。也就是说在半监督学习中,可以使用未知标签的数据提高正确率。
Avtive Learning
在主动学习中,$r>0,t\neq0$。不同于半监督学习的是,这里可以请求从子集$\left\{\overline{x}_{1}, \ldots, \overline{x}_{t}\right\}$得到标签。
GNN简介
之前虽然也记录过关于GNN的笔记,但是那个时候只是关注了GNN本身。最近在看了几篇GNN在Few-Shot Learning任务中的应用之后,对其有了更加深刻的理解。
从“图神经网络”名字中可以看出来,必须要有图,在图上定义神经网络即为“图神经网络”。之前的CNN之所以能够在图像中大放异彩,正是因为图像有着很规则的结构。而CNN具有平移不变性、局部性等特点,能够提取图像深层次的信息。CNN的数学本质为加权求和,且这个加权系数是通过反向传播学习训练出来的,所以才能提取图像深层次特征。其物理本质为提取图形不同频段的特征。而在拓扑结构中,CNN无法得到在哪滑窗、不具备平移不变形等。因此需要GNN,模仿者CNN数学本质为加权求和,GNN对一个中心点及其邻居节点求和(使用邻接矩阵或者拉普拉斯矩阵等),得到当前中心节点的更新值。但是,现在只是求和,并没有进行加权,所以引入了可训练参数,对中心节点及其邻居节点加权求和,得到当前中心节点的更新值。
如何利用中心节点以及其邻居节点得到中心节点的更新值,被称为Aggregator过程;而如何利用当前中心节点的更新值,更新当前中心节点的状态,称为Updater过程。整个过程称为Propagation过程。不同的Propagation过程对应着不同的GNN模型。
这里我们的关注点为如何使用GNN解决Few-shot Learning的问题,所以对于不同的GNN模型不进行探讨。只要我们通过上面的分析过程了解到GNN的本质为中心节点及其邻居节点的加权求和即可,也就是利用邻居节点的信息更新中心节点。
在Few-Shot Learning问题中,是已知少量数据标签的,如何将利用这些数据扩展到无标签数据呢?结合上面我们对GNN的简介,可以很自然的想到,能不能利用GNN,将已有标签的数据信息传播到无标签数据呢?这就是GNN在Few-Shot Learning应用的想法来源。
Meta-Learning简介(待完善)
元学习是一种方法,一种思想,可以用在小样本学习任务上。
GNN与问题的结合
从问题定义小节可以看到,Few-shot Learning、Zero-Shot Learning、Semi-supervised Learning和Avtive Learning这几个问题有着统一的表达式。为了简便起见,我这里只介绍如何与Few-shot Learning的结合。
GNN与Few-shot Learning问题结合的方式大体上可以分为两种。
第一种为:利用知识图谱,常用于Zero-Shot Learning。构建一个节点数目为总类别数目的知识图谱,使用WordNet对类别名称做词嵌入作为图节点的初始特征。学习目标为,图上的每一个节点均为二分类器的权重,其指导信息为预训练CNN模型的最后分类器权重。
第二种为:构建相似图,常用于Few-shot Learning。利用样本之间的相似性,构建节点数目为task中样本总数的图,图上每个节点的特征为该样本的特征。学习目标为,图上的每一个节点(没有标签的样本和有标签的样本)为样本的特征,其指导信息为节点特征与分类器相连后损失最小。通用流程为,首先使用已训练好的CNN模型得到相似图中每一个图像的嵌入特征,相似性度量模块学习如何将集合中的嵌入特征组成一个图,GNN模块传播已知标签的节点特征到未知标签的节点,训练模型使得得到的节点特征与分类器相连后损失最小。
下面对几篇经典以及最新的论文进行分析与对比。
Few-shot Learning With Graph Neural Networks
基本信息
- 标题:Few-shot learning with graph neural networks
- 年份:2018
- 期刊:ICLR
- 标签:相似图、图分类
- 数据:Omniglot、Mini-ImageNet(图结构未知)
创新点
- 使用图神经网络端到端的训练
- 在参数较少的情况下,达到了state-of-art性能
- 扩展模型到半监督学习和主动学习。
创新点来源
Few-Shot Learning问题可以看做是有监督插值问题,节点上的值跟集合中的图片有关,而边通过可训练的相似核得到。结合图结构上的表征学习,提出了这种task-driven的模型。
主要内容
该算法的整体流程如下图所示。网络整体分为CNN、GNN和损失函数三部分。具体而言,CNN模块使用了Resnet网络,GNN部分由三个度量学习->GCN模块组成,损失函数部分为多分类交叉熵函数。其中度量学习中的MLP部分由FC->BatchNorm->Relu->FC->BatchNorm->Relu->FC组成。
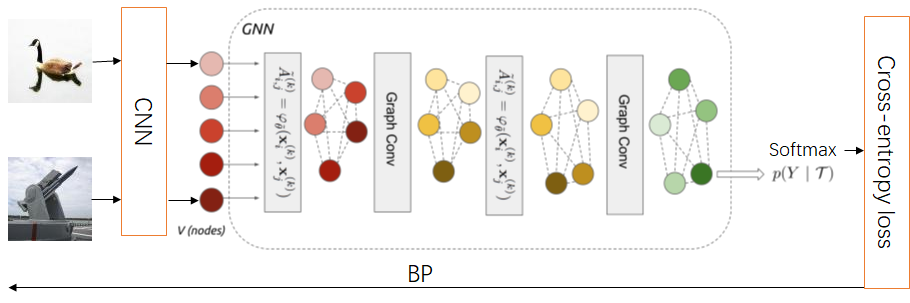
图结构的定义
小样本学习中一个task内含有$qK + t$个数据,为了度量这些数据之间的相似性,建立节点数为$qK + t$的图结构。定义节点$i$和节点$j$之间的相似度为:
其中,$x_i$和$x_j$分别表示顶点$i$和$j$上的数据特征。$\mid \mid \cdot \mid \mid_1$表示一范数,使用一范数表示两个向量的距离,可以保证非负性和对称性。另外,考虑到图结构对GNN中的信息传播有较大的影响,这里将两个向量的一范数结果输入到自定义的神经网络中。并通过最后的损失函数对该神经网络进行优化,从而让网络自己学习到对适合GNN的度量方式。
由此可以得到图中所有节点对之间的相似度,进而得到邻接矩阵$A$。为了防止反向传播过程中梯度爆炸,对$A$中的每一行经过softmax函数。
GNN的定义
定义图G,一般使用点的集合V和边的集合E来描述,即G=(V, E)。定义$A_{ij}$为节点$v_i$和节点$v_j$之间的权重。对于顶点$v_i$,其度定义为它相连的所有边的权重之和,即
利用每个节点度的定义,可以得到一个度矩阵$D$,只有对角线有值。根据$A_{ij}$,可以得到其邻接矩阵$A$。
图结构中,拉普拉斯矩阵的定义式如下:
其中,$D$为对角矩阵,$I$为单位矩阵,$A$为邻接矩阵。
借鉴CNN中卷积操作的数学本质为加权求和,定义GNN中卷积操作如下:
其中,${X^t}$为$t$时刻图上各个顶点的特征矩阵。$\theta$为参数矩阵,${L^{sys}}{X^t}$可以得到各个顶点与其邻居节点的线性组合。而引入参数矩阵$\theta$可以得到各个顶点与其邻居节点的加权求和。
初始特征构造
对于初始节点$i$,其初始特征构造如下:
其中,$\phi$为卷积神经网络,$x_i$为第$i$个图像,$\phi \left( \right)$为卷积神经网络提取出来的图像特征。$h(l) \in \mathbb{R}_{+}^{K}$为类标的one-hot编码。对于未知类标的样本,置$h(l)$为全零向量。考虑到类标中可能蕴含着对于GNN传播过程有利的信息,这里使用$[\cdot]$拼接操作将图像特征和类标的one-hot编码拼接到一起作为初始节点的特征。
损失函数的构造
模型的目的为预测图像$\bar x \in {\cal T}$所对应的类标$Y$,因此网络的最后一层为Softmax层,将节点特征映射到$K$维向量,考虑交叉熵作为损失函数,表达式为
详细步骤
下面结合代码部分,对上述过程进行详细说明。
当数据为omniglot,nway=5 (即$({1})式$中的$K$),num_shots=1 (即$({1})式$中的$q$),batch_size=300,num_test=1 (即$({1})式$中的$t$) 时,构建出的图节点数目为6。整个算法如下:
(1)数据预处理:数据共有1600类,每类有20个样本。因为该数据集为手写体,不同的人手写的方向可能不同,所以对每个数据进行归一化并分别旋转0、90、180、270度扩充样本,最终每类有80个样本。选择其中1200类作为训练集,400类作为测试集。也就是测试集中的类别均未出现在训练集中。
(2)数据准备:从1200类中随机选nway类,每类随机选num_shots个样本(带类标)。从这nway类中在随机选一类,再抽出一个不同的样本(不带类标)作为该task的测试集;将该样本类标单独放在一个变量中,作为该task的测试集类标。以上步骤即可取出一个task的数据,重复batch次,即可得到一个batch的数据。
(3)输入:
1 | batch_x:[batch_size, input_channels, image_size[0], image_size[1]] 存放一个batch内所有未知标签的数据 |
其中,[]符号表示矩阵,其中的数字表示矩阵的大小;而{}符号表示列表,其中的数字表示列表的大小。batch_size为网络的batch大小参数,input_channels为输入图像的通道数,image_size[0], image_size[1]分别代表输入图像的高和宽。
(4)训练过程:
将task内的所有batch_x和batch_xi输入到CNN,分别得到未知标签图像的特征[300, 64]和已知标签图像的特征[300, 64]_{5},将这两者拼接,得到该task内所有数据的特征[300, 64]_{6}。然后将zero_pad和label_yi拼接,得到[300, 5]_{6}。将[300, 64]_{6}和[300, 5]_{6}沿着第二维拼接并增加维度得到[300, 1, 69]_{6},调整维度为[300, 6, 69]。将这个作为输入$X$。
CNN模块 (学习图相似性矩阵):将这个输入$X$经过CNN模型后,得到大小为[300, 6, 6, 1]的矩阵,矩阵的每一行经过softmax函数,即可得到task之内所有样本的相似性矩阵。将该矩阵与单位矩阵拼接得到大小为[300, 12, 6]的矩阵,该矩阵作为图相似性矩阵$W$。
GNN模块 (信息传播):将$W$和$X$做矩阵相乘得到新$X$,维度为[300, 12, 69],调整维度为[300x6, 69x2] (300x6可以理解为batch内所有的样本,batch_size x n_way x num_shots + 1),经过fc层 ( 作用为降维) 输出得到[300x6, 48],resize可以得到[300, 6, 48]。旧$X$和新$X$拼接得到维度为[300, 6, 69+48]。作为下一次的输入$X$。
重复上述CNN模块和GNN模块三次,得到[300, 6, 5]的out,返回out[:, 0, :]。即维度[300, 5]。因为对于batch内的每个task,其第一项为待分类样本。这样就得到了一个batch之内所有task内待分类样本的标签。
输入out[:, 0, :]和label_x到Pytorch中的NLLLoss损失函数,得到损失值,并反向传播。
这里有两个细节,在CNN模块中使用了学习到的相似矩阵和单位矩阵拼接作为最后的图相似性矩阵;在GNN模块将旧$X$和新$X$拼接得到得到最后的$X$。猜测这样做可以尽可能的在训练过程中保持有用信息并增加新的信息,防止过拟合的同时也可以防止欠拟合。
(5)测试过程:
值得注意的是,测试过程数据准备过程与训练过程一样,唯一不同的是,测试过程从用于测试的400个类中抽取数据组成task,而训练数据从用于训练的1200类中抽取数据组成task。也就是说,在测试过程中,每个task均是知道nways*num_shots个数据的类标的,去预测某一个未知标签样本的标签(这个标签一定属于被选中的nways类中的一个)。
Semi-supervised Learning学习代码与Few-Shot Learning代码区别在于,对于输入数据
batch_yi的处理方式不同。对于Semi-supervised Learning,num_shots个数据中前unlabeled_extra个数据,其对应在batch_yi的标签为全0向量 (即没有标签信息)。例如有3个unlabeled_extra数据,要想组成5_shots,每个task需要5+3+1个数据。
缺点
- 只考虑了$t=1$的情况
- 损失函数只考虑了待分类数据,而没有把有标签的数据考虑到损失函数中。这里将有标签数据的标签加入到了数据特征中,文章说标签可能蕴含了对于分类有用的信息。
启发
- 对于没有图结构的数据,要想使用GNN解决相关问题,必须手动构建图结构。而构建图神经网络过程中,一种方法是度量样本的相似性。注意这个度量要考虑对称性、非负性、自身与自身是否相似。另外,现有的论文都推荐使用神经网络度量样本间的相似性。比单独的使用范数等数学距离度量方式产生的图结构可能更适合这个任务。
思考
思考1:Few-Shot Learning并不是说训练样本少,而是batch内的每一个task见到的样本少。
思考2:如何理解元学习在Few-Shot Learning中的应用?
元学习定义:学习不同task之间的共同知识,扩展到未知类中。例如在本例中,通过元学习方法学习如何将未知标签的数据分为nways类中。然后扩展到测试集中(测试集中的类别在训练集中均没有见过)。这和元学习的目标一致。但是元学习有一个大前提:假设训练过程中的task和测试过程中的task满足同一个分布。
思考3:如何理解GNN在Few-Shot Learning(Semi-supervised Learning)中的应用?
在Few-Shot Learning(Semi-supervised Learning)中,问题均为已知部分数据的标签,未知部分数据的标签。无标签节点部分被动的接受者来自相邻节点的特征,改变自己的特征,从而影响着自己的label。而特征矩阵左乘图神经网络中的拉普拉斯矩阵,正是对各个节点的特征进行线性组合,而右乘以参数矩阵,可以得到各个节点的特征的加权线性组合,从而获得更加高阶更加复杂的特征。使用GNN最终学到的特征传播过程可以得到未知标签样本的特征,进一步可以得到预测标签。

